
直到上个十年初,研究的主要驱动力还包括直接收集的原始数据。然而,随着越来越多的数字数据随着更好的实践和对公共数据库越来越多的贡献而产生,二手数据(贡献并存储在大型在线数据库中)现在已成为世界各地研究人员的主要工具之一。现在,人们利用二手数据平台查找相关数据,并以比以往更快的速度推进知识发展。
因此,数据库已成为研究项目的重要组成部分。数字基础设施的发展也为以数字格式存储和利用数据提供了更便捷的方式。
利用在线数据库可以更快地找到相关数据,而无需花费重做实验和实际研究的费用。这使得研究人员和社会大众可以更方便地获取数据。
要了解如何有效地将数据库用于研究,首先需要确定数据库的实际含义。在这里,数据库是结构化存储数据和支持存储的基础设施的组合。这种基础设施一般包括应用程序和支持存储的软件以及相关计算机。
如今,研究机构和公司让研究人员能够利用不同的基础设施,为多种不同目的聚合更多的数据库。这些集合体被称为数据存储库(data repositories);这是我们在了解如何高效使用数据库时使用的最重要术语之一。
这类研究资料库主要有两种用途。
- 查找与研究项目相关的数据
- 为提高透明度和重复使用贡献数据
这两个主要的数据库用途是实现流程的关键所在,也是帮助开展研究的关键所在。因此,为了简化数据库如何帮助你解决与数据有关的问题,下面的图表将针对这些具体问题进行说明。
数据库如何帮助研究人员回答一些最重要的数据问题。
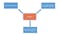
查找与研究相关的数据
现在,对于研究人员来说,在数据库中查找相关数据非常简单。事实上,经常会有关于如何使用数据平台的视频教程,请务必观看。在开始数据搜索之前,还有一个非常重要的方面,那就是确定可能与数据相关的研究领域;这意味着你需要了解与数据相关的领域以及相关术语,这些术语应该写在纸上或作为数字文档供进一步使用。建议将这些相关术语和领域信息整理成一个简单的 Word、记事本或 Excel 文件。这些内容以后可以纳入数据搜索旅程的各个部分。
- 预先定义关键词
- 使用数据库搜索功能
- 过滤结果
下面是一个使用欧洲分子生物学实验室(EMBL)平台的数据存储库界面示例。
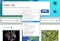
因此,每位研究人员的第一步都应该是定义与特定研究项目相关的数据。这意味着,应使用预定义的数据来解决特定的研究问题。这第一步涉及多个方面:其一是列出用于发现数据的关键字。这些关键词通常包含在研究项目的标题以及稿件的摘要、结果和讨论中。
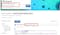
以下是用于查找相关胰岛素/II 型糖尿病数据的关键词示例--[ INSULIN, HORMONE, DIABETES,TYPE 2, PROTEIN]。其中一些关键词还可用于过滤,因此可使用下拉选项对结果进行过滤。随后的结果只输出基因表达数据,因此需要在搜索框中输入其他词才能找到相关数据。
下面是一些其他数据资源库的链接,这些数据资源库侧重于自然科学、社会科学和工程学的不同领域。这些资源库大多支持开放科学,便于研究人员在其特定领域内查找数据。
- NCBI - 生物医学和基因组数据
- EMBL - 生物医学和分子生物学数据
- Uniprot - 蛋白质/氨基酸数据
- Zenodo - 生命科学数据
- Reactome - 生物相互作用和注释数据
- Paleoportal - 古生物学数据
- Chembl - 化学信息学数据
- Re3data - 从社会和人文科学到医学数据集
- Dhsprogram - 空间/地理学数据存储库
- Harvard Dataverse - 来自不同领域(生命科学、法律、工程、社会科学和许多其他领域)的数据集和数据服务器集合。
- Openicspr - 社会、行为和健康相关数据库
- CERN data portal - 物理数据
- HEP Data - 物理数据
- Google datasets 是在线搜索不同数据源的有效方法,利用这个强大的搜索引擎可以找到适用的数据。
检索数据
- 评估可用文件 - 一旦确定你需要的数据存在于某个存储库中,下一步就是评估其数量和特征。为此,有必要确保数据以完整的形式存在,有足够的数据来回答你的研究问题,并且原始数据来源的作者提供了数据的所有相关信息,使其适用于你的使用。最后,一定要查看相关使用许可中包含的数据使用条款。
- 选择正确的数据格式
- 下载数据以备将来使用
提供数据以提高透明度和重复使用
有效使用数据库及其资料库的第二种方法是在需要和适用的情况下上传和提供数据。提供数据意味着将数据提供给其他研究人员重复使用。
这是改进某些研究领域的最佳方法之一,可以让许多研究人员从不同角度、使用不同工具和方法进行分析。所有成果出版物都应注明原始数据提供者,因此这一原则既能更好地利用研究数据,又能提高提供者的学术知名度和成果。
提供数据的相关信息
在任何数据库中发布数据最重要的一个方面就是元数据。这些数据将最大限度地向所有未来用户展示所发布数据的背景。公共数据的任何再利用都高度依赖于这些数据所代表的内容、使用了哪些实验和方法、数据集中使用了哪些术语以及许多其他细节。
定义数据许可证
在发布任何数据之前,请决定你希望在哪些条件下向他人提供数据。定义他人将来可以使用数据的许可证。在设置许可之前,你必须了解哪些许可是常用的,其条款是什么。
以下是一些需要牢记的许可证:
- CC 系列
- Apache 2.0
- MIT
- BSD - 2
- BSD - 3
- GNU
- EU Public 1.1
- ISC
- Educational community license
CC 系列、Apache、MIT、GNU 都是许可类型。它们被视为许可证系列,允许公众重用数据。许可证允许并促进数据的传播,以供未来研究和重复使用。
即使数据被公开重用,引用数据也始终是最好的做法。与研究报告的作者类似,数据作者也是贡献者,在使用他们的数据时也要注明出处。
创建自己的研究数据库存储库
创建自己的数据存储库的最佳平台之一是 GitHub。尽管 GitHub 是著名的代码共享和软件开发平台,但它的最佳功能之一就是存储和共享数据。
研究人员可以创建自己的存储库,在其中存储和共享数据。在实际存储数据之前,先确定数据是私人数据或不可共享给他人的数据,还是可与他人共享的公共数据。
GitHub 上的数据存储库也是组织数据的最佳方式之一,它可以保存数据修订、变更的所有相关信息,并将数据整合起来以供将来重用。其他可供研究人员选择的类似网站还有 Gitlab、SourceForge 和 Launchpad。

最后,将数据集、数据信息、研究方法信息、代码和补充文件存储在像 GitHub 这样的数据存储平台上,可以改善任何研究项目的工作流程。它们能确保数据存储在安全的地方,并且井井有条。在研究成果发表之前,最好将资源库保持私有(Github 上有两个选项:私有或公共资源库)。研究发表后,作者可以决定是否将其资源库公开,以提高透明度和潜在的数据再利用。
注: 数据的数字化使在线数据库成为数据存储、分析和组织的主要工具之一。每天都有越来越多的数字数据产生。使用数据库查找数据、存储和组织数据的技能对于任何现在或未来的研究人员来说都是必不可少的。
